メトリクスを監視するには¶
Incus はすべての実行中のインスタンスについてのメトリクスといくつかの内部メトリクスを収集します。 これは CPU、メモリー、ネットワーク、ディスク、プロセスの使用量を含みます。 Prometheus で読み取って Grafana でグラフを表示するのに使うことを想定しています。 利用可能なメトリクスの一覧は提供されるメトリクスを参照してください。
クラスタ環境では、 Incus はアクセスされているサーバー上で稼働中のインスタンスの値だけを返します。ですので、各クラスタメンバーから別々にデータを取得する必要があります。。
インスタンスメトリクスは /1.0/metrics エンドポイントを呼ぶと更新されます。
複数のスクレイパーに対応するためメトリクスは 8 秒キャッシュします。メトリクスの取得は比較的重い処理ですので、影響が大きすぎるようならデフォルトの間隔より長い間隔でスクレイピングすることを検討してください。
生データを取得する¶
Incus が収集した生データを見るには、1.0/metrics エンドポイントに incus query コマンドで問い合わせてください。
~$ incus query /1.0/metrics# HELP incus_cpu_seconds_total The total number of CPU time used in seconds.# TYPE incus_cpu_seconds_total counterincus_cpu_seconds_total{cpu="0",mode="system",name="u1",project="default",type="container"} 60.304517incus_cpu_seconds_total{cpu="0",mode="user",name="u1",project="default",type="container"} 145.647502incus_cpu_seconds_total{cpu="0",mode="iowait",name="vm",project="default",type="virtual-machine"} 4614.78incus_cpu_seconds_total{cpu="0",mode="irq",name="vm",project="default",type="virtual-machine"} 0incus_cpu_seconds_total{cpu="0",mode="idle",name="vm",project="default",type="virtual-machine"} 412762incus_cpu_seconds_total{cpu="0",mode="nice",name="vm",project="default",type="virtual-machine"} 35.06incus_cpu_seconds_total{cpu="0",mode="softirq",name="vm",project="default",type="virtual-machine"} 2.41incus_cpu_seconds_total{cpu="0",mode="steal",name="vm",project="default",type="virtual-machine"} 9.84incus_cpu_seconds_total{cpu="0",mode="system",name="vm",project="default",type="virtual-machine"} 340.84incus_cpu_seconds_total{cpu="0",mode="user",name="vm",project="default",type="virtual-machine"} 261.25# HELP incus_cpu_effective_total The total number of effective CPUs.# TYPE incus_cpu_effective_total gaugeincus_cpu_effective_total{name="u1",project="default",type="container"} 4incus_cpu_effective_total{name="vm",project="default",type="virtual-machine"} 0# HELP incus_disk_read_bytes_total The total number of bytes read.# TYPE incus_disk_read_bytes_total counterincus_disk_read_bytes_total{device="loop5",name="u1",project="default",type="container"} 2048incus_disk_read_bytes_total{device="loop3",name="vm",project="default",type="virtual-machine"} 353280...Prometheusをセットアップする¶
生のメトリクスを収集し保管するには、Prometheusをセットアップするのが良いです。 メトリクス API エンドポイントを使ってメトリクスを収集するように設定できます。
メトリクスエンドポイントを公開する¶
/1.0/metrics API エンドポイントを公開するには、利用可能にするアドレスを設定する必要があります。
そのためには、core.metrics_addressサーバー設定オプションかcore.https_addressサーバー設定オプションのいずれかを設定できます。
core.metrics_addressオプションはメトリクスのみを公開し、core.https_addressは完全な API を公開します。
ですので、完全な API とメトリクスの API で別のアドレスを使いたい場合、あるいはメトリクスの API のみ公開し完全な API は公開したくない場合はcore.metrics_addressオプションを設定するのが良いです。
たとえば、完全な API を8443ポートで公開するには、次のコマンドを入力します:
incus config set core.https_address ":8443"
メトリクス API エンドポイントのみを8444ポートで公開するには、次のコマンドを入力します:
incus config set core.metrics_address ":8444"
メトリクス API エンドポイントのみを指定した IP アドレスとポートで公開するには、次のようなコマンドを入力します:
incus config set core.metrics_address "192.0.2.101:8444"
メトリクス用証明書の追加¶
/1.0/metrics API エンドポイントの認証はメトリクス証明書で行われます。
メトリクス証明書(タイプがmetrics)は、メトリクス専用でインスタンスや他の Incus のエンティティの操作には使用できないという点でクライアント証明書(タイプがclient)とは異なります。
新しい証明書は以下のように作成します:
openssl req -x509 -newkey ec -pkeyopt ec_paramgen_curve:secp384r1 -sha384 -keyout metrics.key -nodes -out metrics.crt -days 3650 -subj "/CN=metrics.local"
注釈
上のコマンドは OpenSSL 1.1.0以降が必要です。
作成後、証明書を信頼済みクライアントのリストにmetricsというタイプを指定して追加する必要があります:
incus config trust add-certificate metrics.crt --type=metrics
あなたの環境で TLS クライアント証明書を要求することができない場合、/1.0/metrics API エンドポイントを認証されていないクライアントで利用可能にできます。
お勧めはしませんが、API エンドポイントに誰がアクセスできるかを別の手段で制御できるのであれば許容できるかもしれません。メトリクス API の認証を無効にするには以下のようにします:
# Disable authentication (NOT RECOMMENDED)
incus config set core.metrics_authentication false
メトリクス用証明書をPrometheusで利用可能にする¶
Prometheus を Incus サーバーと別のマシンで稼働させる場合、必要な証明書を Prometheus のマシンにコピーする必要があります。
作成したメトリクス用証明書(
metrics.crt)と鍵(metrics.key)/var/lib/incus/に置かれている Incus サーバー証明書(server.crt)
これらのファイルを Prometheus からアクセスできるtlsディレクトリー、たとえば、/etc/prometheus/tlsにコピーしてください。
次の例のコマンドを参照してください:
# tls ディレクトリーを作成
mkdir /etc/prometheus/tls/
# 新規に作成された証明書と鍵を tls ディレクトリーにコピー
cp metrics.crt metrics.key /etc/prometheus/tls/
# Incus サーバー証明書を tls ディレクトリーにコピー
cp /var/lib/incus/server.crt /etc/prometheus/tls/
# ファイルを Prometheus からアクセス可能にします
chown -R prometheus:prometheus /etc/prometheus/tls
PrometheusをIncusからデータ収集できるように設定する¶
最後に、 Incus をターゲットとして Prometheus の設定に追加する必要があります。
そのためには、/etc/prometheus/prometheus.yamlを編集し、Incus にジョブを追加します。
必要な設定は以下のようになります:
global:
# デフォルトでどれぐらい頻繁にターゲットからデータ収集するか。Prometheus のデフォルト値は 1m です。
scrape_interval: 15s
scrape_configs:
- job_name: incus
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['foo.example.com:8443']
tls_config:
ca_file: 'tls/server.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
# XXX: server_name は targets のホスト名が証明書でカバーされない
# (証明書の SAN リストに含まれない)場合は必須です
server_name: 'foo'
注釈
Incus サーバ証明書がtargetsリスト内で使用するのと同じホスト名を含まない場合はserver_nameの指定は必須です。
scrape_intervalは Grafana Prometheus データソースではデフォルトで 15s と想定されています。 別のscrape_intervalの値を使う場合、Prometheus の設定と Grafana Prometheus データソースの設定の両方を変更する必要があります。 そうしないと Grafana の$__rate_intervalの値が正しく計算されず、それを使ったクエリでno dataというレスポンスを生じるかもしれません。Incus のサーバー証明書に
targetsリストで使用されるのと同じホスト名を含まない場合、server_nameを指定する必要があります。 これを確認するには、server.crtを開いて Subject Alternative Name (SAN) セクションを確認してください。
例えば、server.crt が以下の内容を持つとします:
~$ openssl x509 -noout -text -in /etc/prometheus/tls/server.crt... X509v3 Subject Alternative Name: DNS:foo, IP Address:127.0.0.1, IP Address:0:0:0:0:0:0:0:1...Subject Alternative Name (SAN) リストが targets リスト(foo.example.com)のホスト名を含んでいないので、 server_name ディレクティブを使用して比較に使用する名前を上書きする必要があります。
以下は複数の Incus サーバーのメトリックを収集するために複数のジョブを使用する prometheus.yaml の設定例です:
global:
# デフォルトでどれぐらい頻繁にターゲットからデータ収集するか。Prometheus のデフォルト値は 1m です。
scrape_interval: 15s
scrape_configs:
# abydos, langara, orilla は最初にabydosからブートストラップした単一クラスタで
# (ここでは`hdc`と呼びます)、このため3ノードで`ca_file`と`server_name`を共有しています。
# `ca_file`は Incus クラスタの各メンバー上に存在する`/var/lib/incus/cluster.crt`
# ファイルに対応しています。
#
# 注意: `project`パラメータが指定されると、`default`プロジェクトをオーバーライドします。
# 指定しないと、すべてのプロジェクトのデータを収集します。
#
# 注意: クラスタの各メンバーはローカルで稼働するインスタンスのメトリクスだけを提供します。
# これが`incus-hdc`クラスタが3つのターゲットを一覧表示している理由です。
- job_name: "incus-hdc"
metrics_path: '/1.0/metrics'
params:
project: ['jdoe']
scheme: 'https'
static_configs:
- targets:
- 'abydos.hosts.example.net:8444'
- 'langara.hosts.example.net:8444'
- 'orilla.hosts.example.net:8444'
tls_config:
ca_file: 'tls/abydos.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'abydos'
# jupiter, mars, saturn は3つのスタンドアロンの Incus サーバーです。
# 注意: これらでは`default`プロジェクトのみが使用されているため、プロジェクトの設定は省略しています。
- job_name: "incus-jupiter"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['jupiter.example.com:9101']
tls_config:
ca_file: 'tls/jupiter.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'jupiter'
- job_name: "incus-mars"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['mars.example.com:9101']
tls_config:
ca_file: 'tls/mars.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'mars'
- job_name: "incus-saturn"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['saturn.example.com:9101']
tls_config:
ca_file: 'tls/saturn.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'saturn'
設定を編集後、Prometheus を再起動する(たとえば、systemctl restart prometheus)とデータ収集を開始します。
Grafanaダッシュボードをセットアップする¶
メトリクスデータを可視化するには、Grafanaを設定します。 Incus は、Prometheus によって収集された Incus メトリクスと Loki からのログエントリを表示するように設定されたGrafanaダッシュボードを提供します。
注釈
このダッシュボードはPrometheusとLokiの両方をGrafana内のデータソースとして設定したGrafana 8.4以降が必要です。
Grafana内にプレイスホルダーのLokiデータソースを追加し、完全にセットアップされたLokiサーバーがない環境のダッシュボードをインポートできます。インポート後、ダッシュボード下部のログのセクションを削除し、その後プレイスホルダーのLokiデータソースを削除してください。
LokiへのIncusのログ出力は関連するサーバー設定で設定できます。
Grafana のドキュメントを参照して、インストールとサインインの手順を確認してください:
次の手順でIncusダッシュボードをインポートします:
Prometheus をデータソースとして設定します:
Configuration > Data sourcesに移動します。
Add data sourceをクリックします。
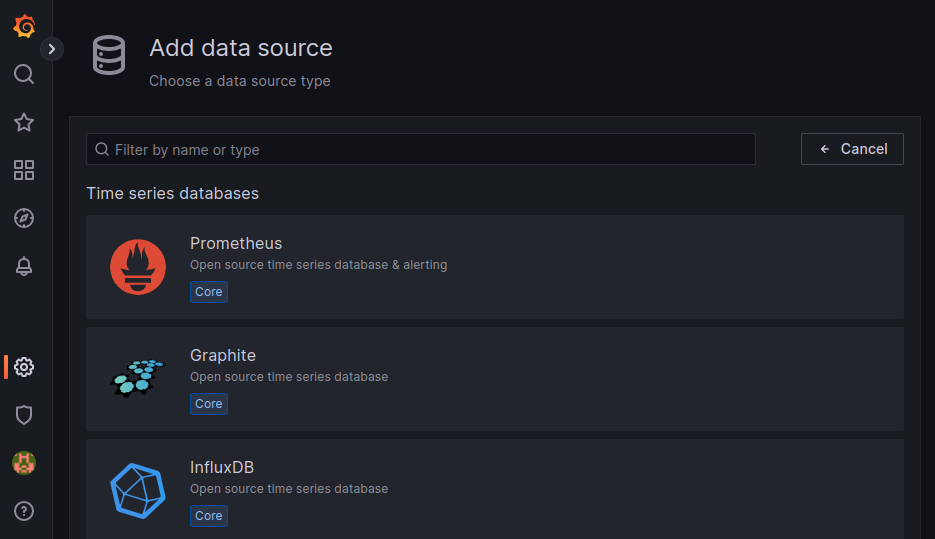
Prometheusを選択します。
Prometheusがローカルで動いている場合URLフィールドに
http://localhost:9090/を入力します。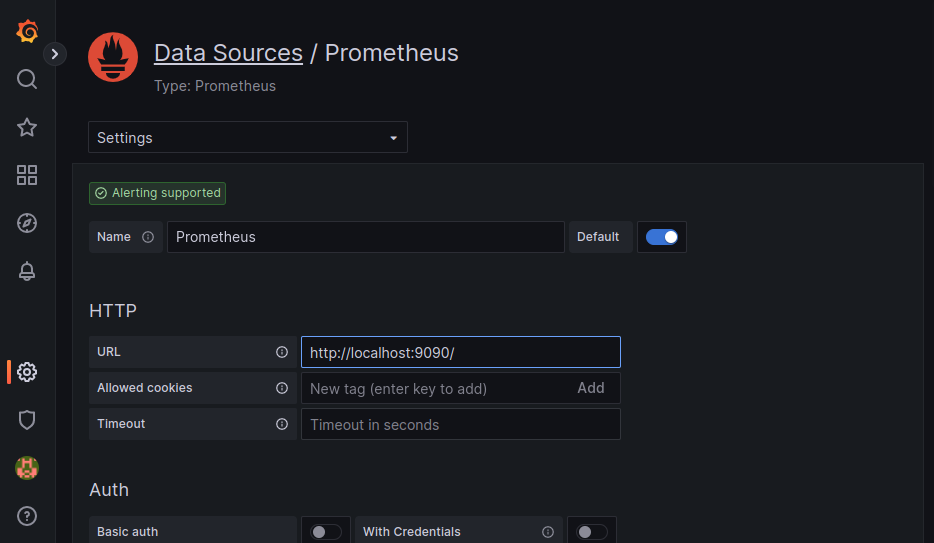
他のフィールドはデフォルトの設定のままにし、保存&テストをクリックします。
Loki をデータソースとして設定します:
Configuration > Data sourcesに移動します。
Add data sourceをクリックします。
Lokiを選択します。
Lokiをローカルで動かす場合URLフィールド内で
http://localhost:3100/を入力します他のフィールドはデフォルトの設定のままにし、保存&テストをクリックします。
Incus のダッシュボードをインポートします:
Dashboards > Browseに移動します。
Newをクリックし、Importを選択します。
Import via grafana.comフィールドにダッシュボード ID
19727を入力します。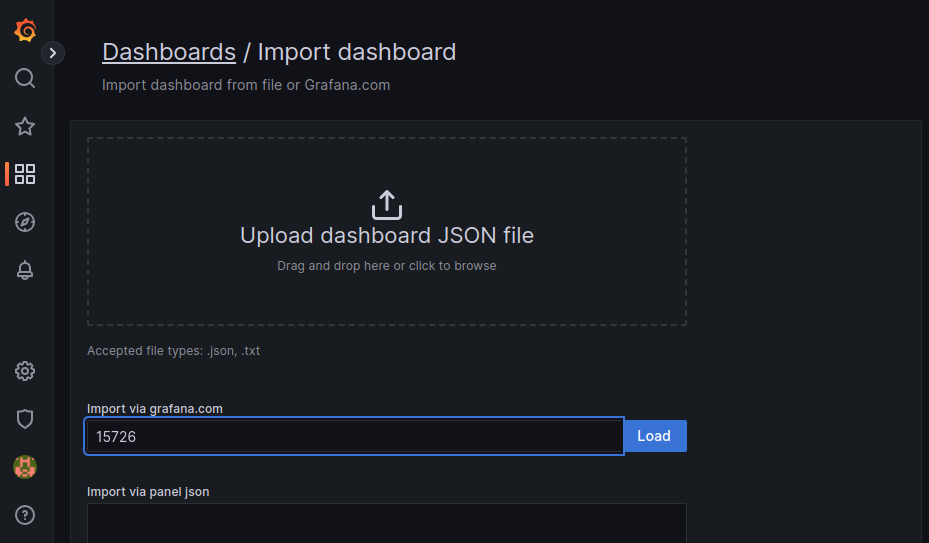
Loadをクリックします。
Incusのドロップダウンメニューから、設定した Prometheus と Loki のデータソースを選択します。
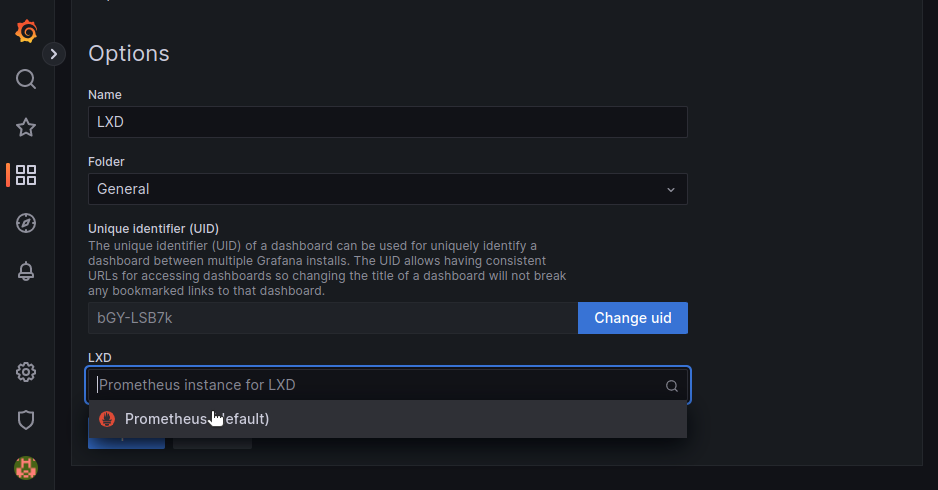
Importをクリックします。
これで Incus ダッシュボードが表示されるはずです。 プロジェクトを選択し、インスタンスによってフィルタリングすることができます。
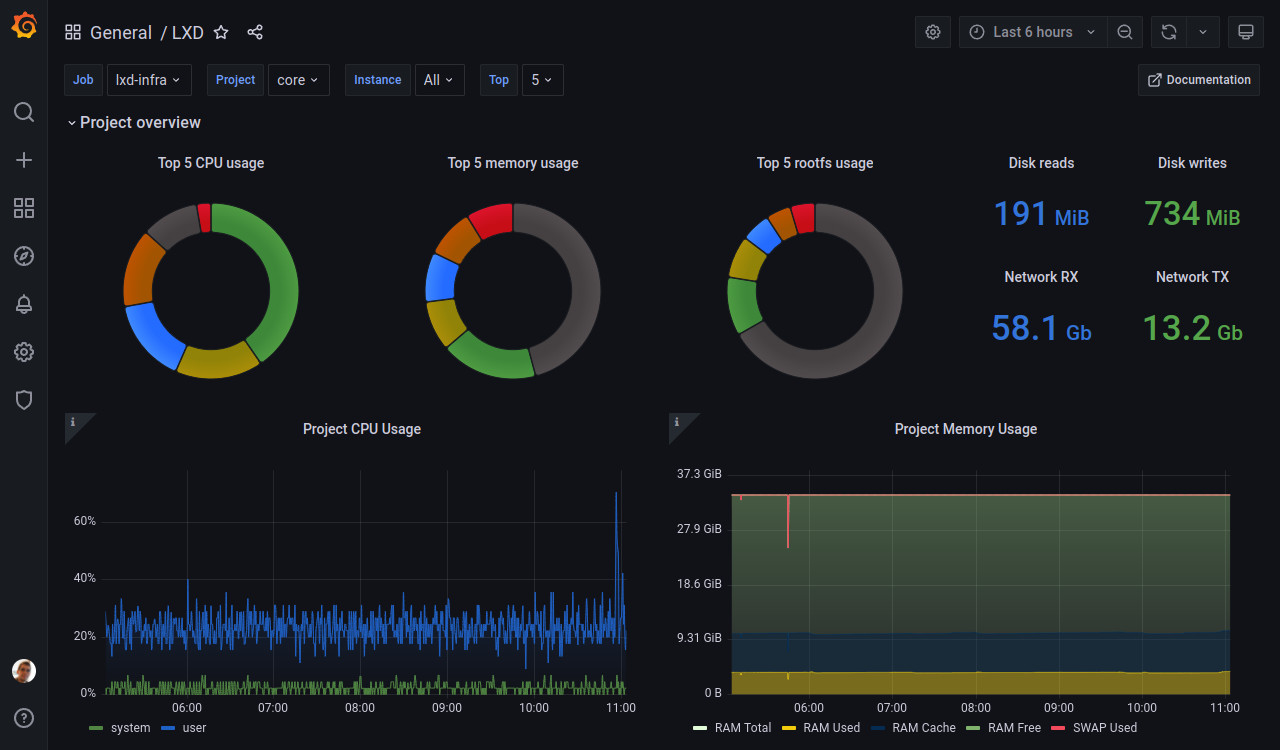
ページの下部で、各インスタンスのデータを見ることができます。
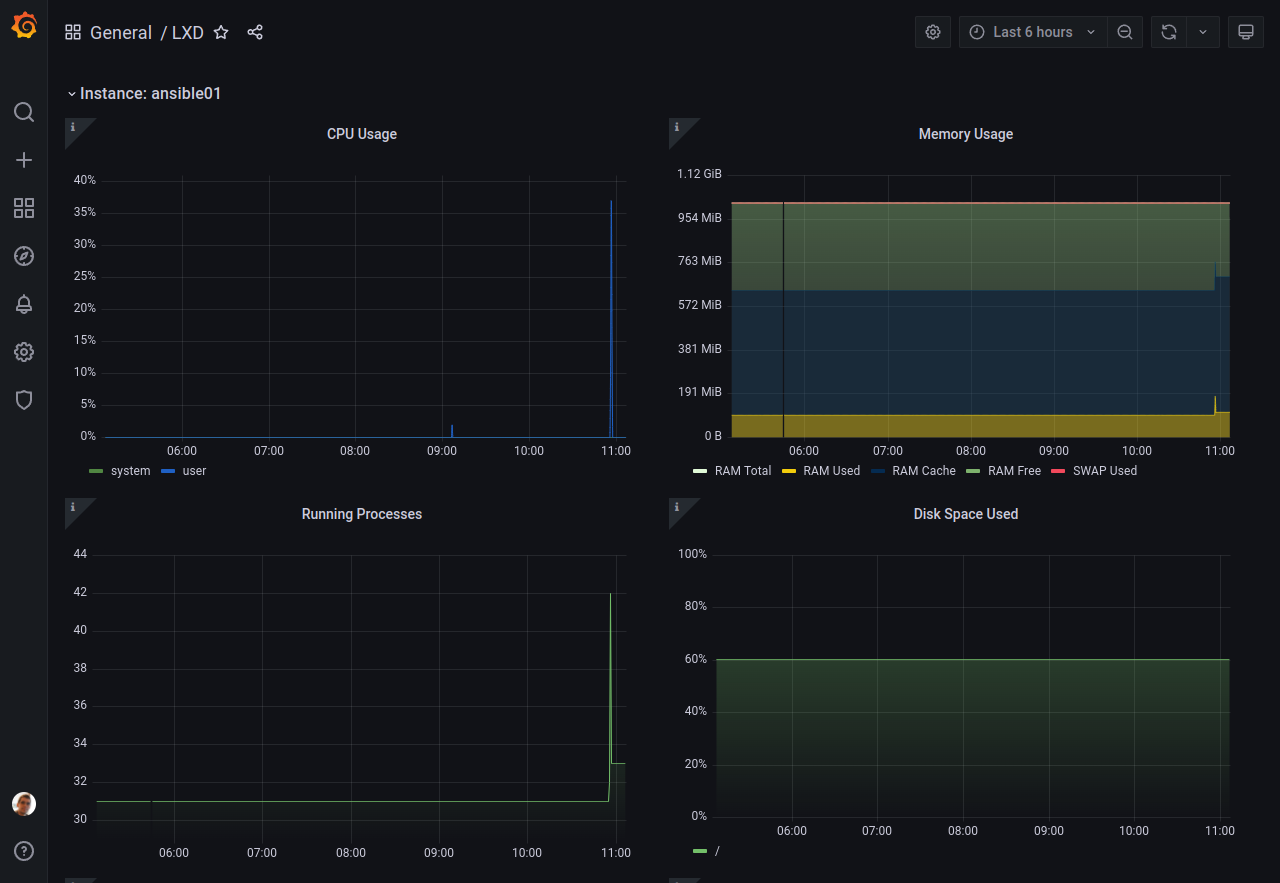
注釈
ダッシュボードの Loki の部分を適切に動かすには、instanceフィールドをPrometheusのジョブ名と一致させる必要があります。
instanceフィールドはlogging.*.target.instance設定キーで変更できます。